
It s*cks to find datasets – Build your own YouTube dataset instead
Hands-on end-to-end ML project for the busy learner – Part I

If you’re like me, you hate googling, kaggling and whatever-else-ing to find proper data for your great project that popped out of your head during showering.
So to spare you some pain that comes with working with data, I’ll show you how to create your own dataset1 from YouTube (here’s the link to the repo).
You’ll learn to:
create an API key and a service account in Google Cloud,
collect video data (e.g. title, view count) with the YouTube Data API using Python,
and store the data in BigQuery (data warehouse, part of Google Cloud).
I know what you’re thinking, and yes – these skills will indeed increase your awesomeness by +1002 points.
Three more things:
Everything we’re doing here is totally free.
I’ll assume you have basic Python knowledge so I won’t explain simple stuff (e.g. variables, classes, methods).
The article may seem long, but don’t worry, there’s lots of BIG screenshots taking up BIG space.
Let’s go! 💪
1. Create your YouTube API key & service account in Google Cloud
1.1 Register a Google Cloud account
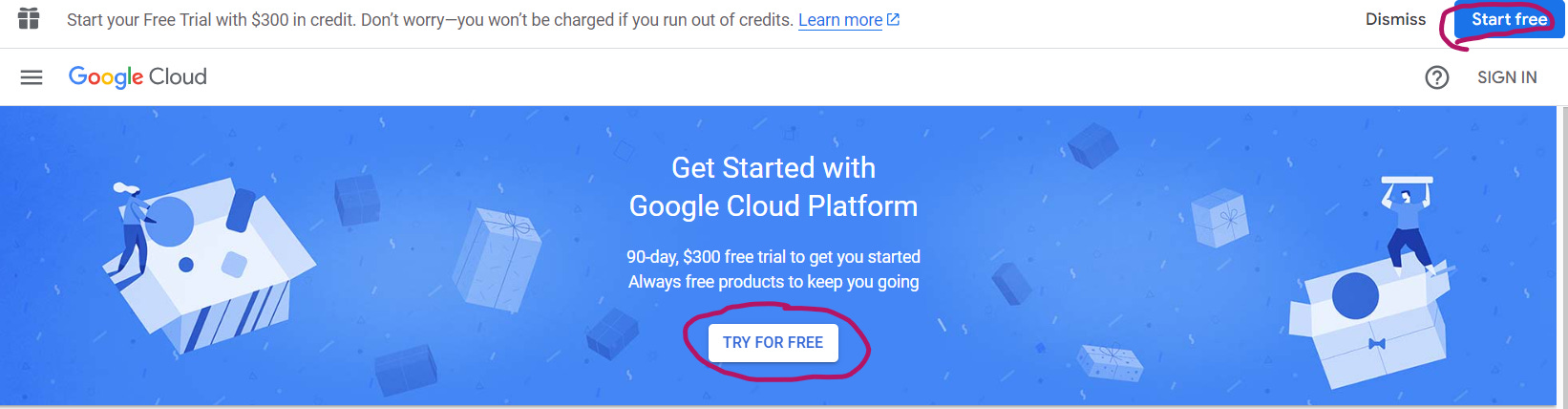
To get access to the YouTube Data API, you’ll have to create a Google Cloud account.
Click on either the “TRY FOR FREE” or the “Start free” button that I so beautifully circled:3
Go through the guided steps to set up your account.
(I won’t insert screenshots here, because the process is self-explanatory.)
(Also – unlike some Google experiences – it won’t be painful.)
(Pinky promise.)
And don’t let “free” scare you; you won’t have to pay for anything even later on unless you decide otherwise.
With the free trial, you and your wallet are both safe.
1.2 Generate an API key so you can use the YouTube API
Okay.
Without an API key, you can’t collect data with the YouTube API.
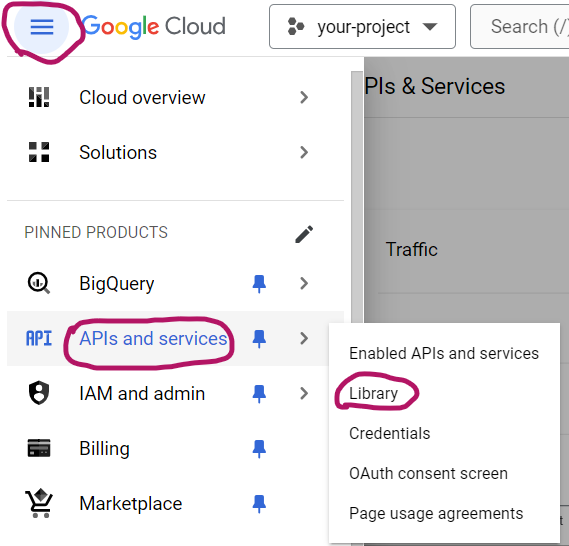
In your Google Cloud account, click on the hamburger menu icon, then pick “Library“ under “APIs and services”:
Search for “YouTube Data API v3“:
The search result will look like this:
Click on the search result, then enable the API:
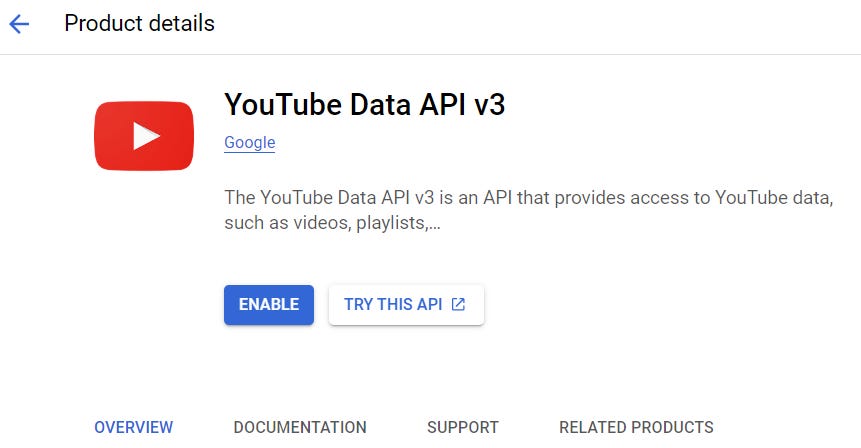
At this point the API creation process can go one of two ways; let’s call them Way 1. and Way 2.
1.2.1 Way 1.
If you see this option, click “Create credentials” (otherwise go to “1.2.2 Way 2.“):
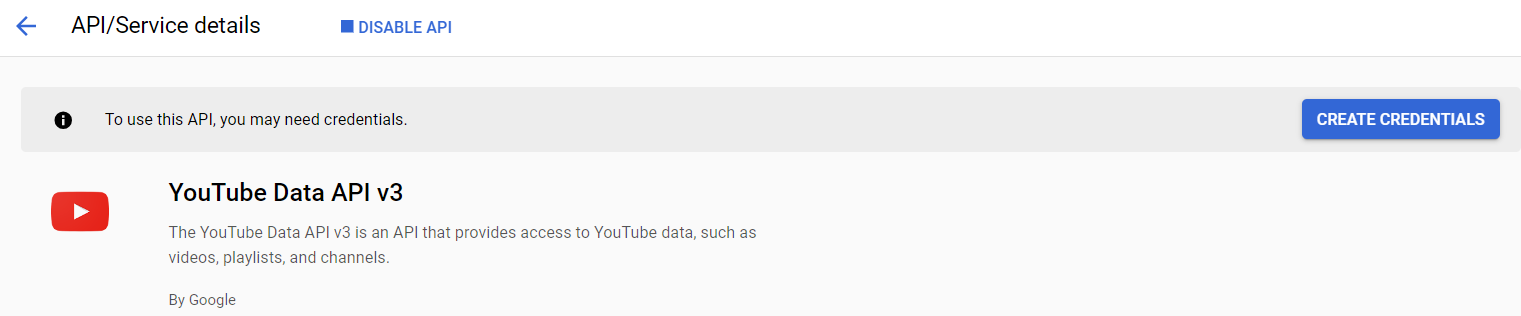
Make sure to select the YouTube Data API v3 as the API, then choose “Public data”:
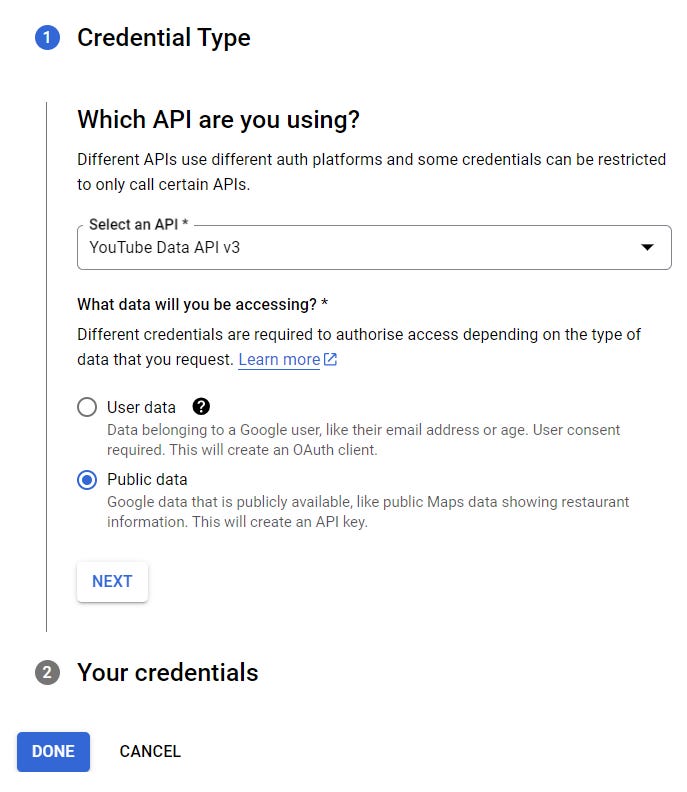
For our use case, “Public data” is the right choice, because we’ll collect data from a YouTube channel we don’t own.
Once you click “Next”, you’ll receive your API key (intentionally not shown in the screenshot, but it’ll be there, trust me):
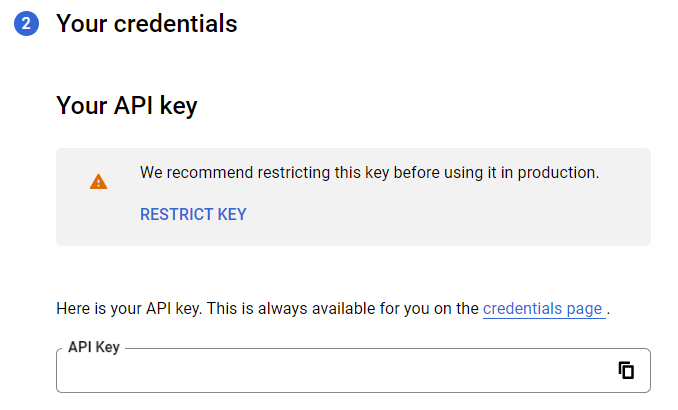
Click “Done”, aaand you’re good to go! Just make sure you can access the API key, because the Python script we’re writing will need it.
Skip “1.2.2 Way 2.“, and go to the “1.2.3 Set up API key restrictions for safety” section to continue.
(Or read “1.2.2 Way 2.“ to learn where and how you can create other API keys.)
1.2.2 Way 2.
Go to the credentials panel under “APIs and services”:
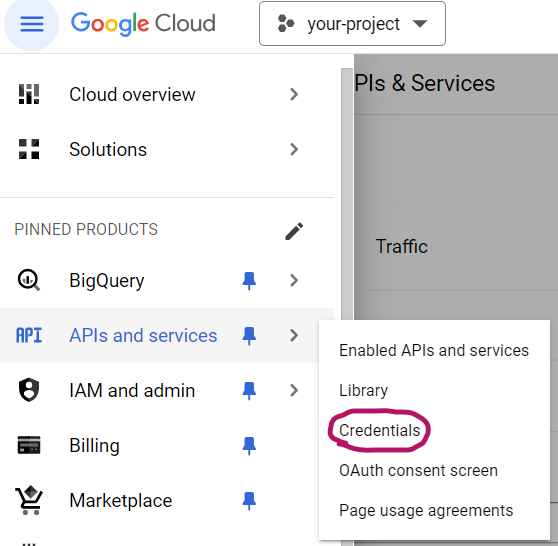
Choose “CREATE CREDENTIALS”, then “API key”:
And just like that, in a nice pop up, your API key will await you. Just make sure you can access the API key, because the Python script we’re writing will need it.
1.2.3 Set up API key restrictions for safety
If you head to the credentials page, you can restrict your API key for safety reasons.
To do that, click on the three dots corresponding to your API key, and choose “Edit API key” or just click on the API key’s name:

For instance, I chose that my API key can be used exclusively for the YouTube API:
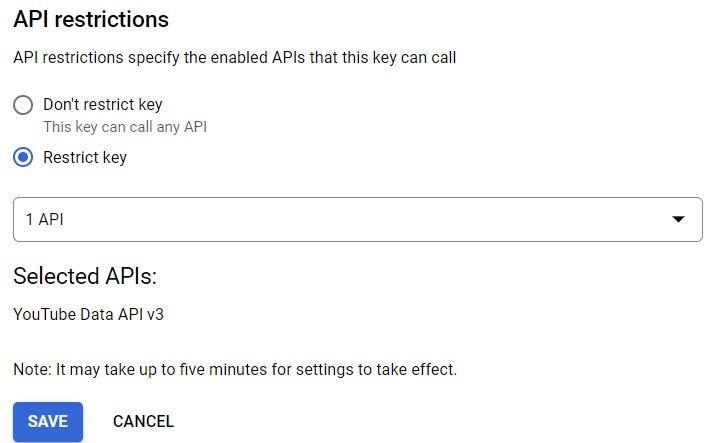
Oh, and you can name your API key whatever you like, too!
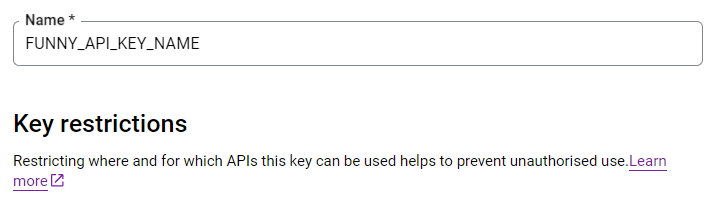
1.3 Create a service account so you can load data to BigQuery
At this point you’re the happy owner of an API key that grants you access to the YouTube API.
(The coolest version (v3) at that!)
(If this doesn’t make you a cool person, I don’t know what does.)
In order to let your script load data into your BigQuery table (which is not yet created, so don’t worry, you didn’t miss anything), you need a so-called service account.
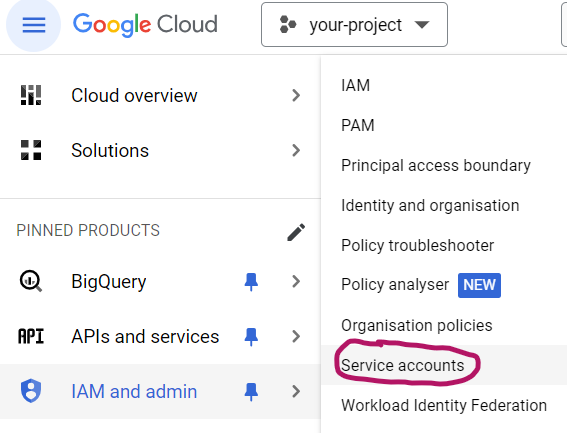
To create one, choose “Service accounts” under “IAM and admin“:
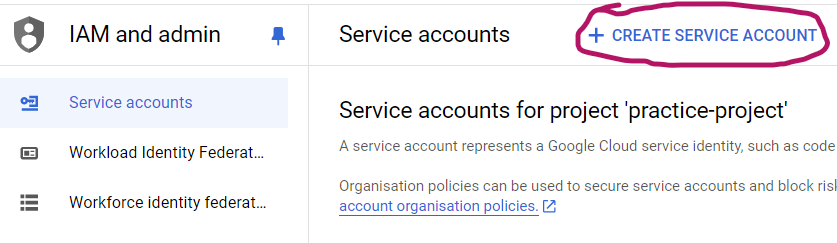
There click on “CREATE SERVICE ACCOUNT“:
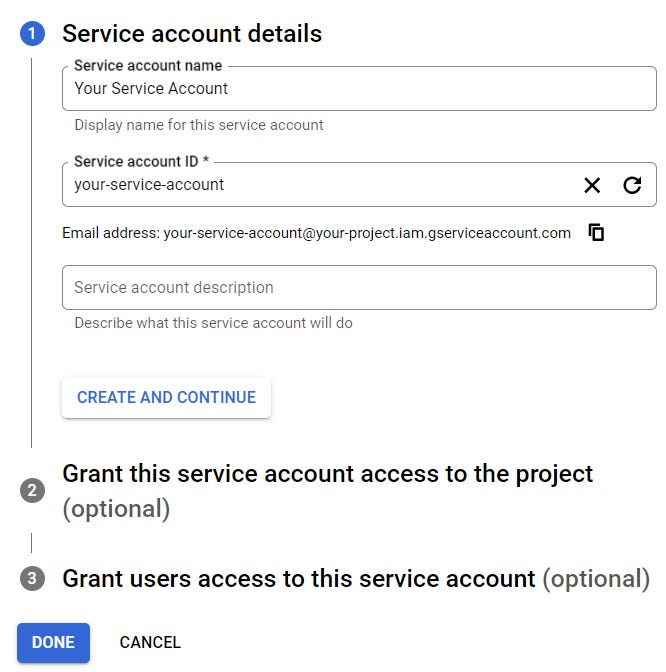
Name your service account (the “Service account ID” field will be automatically populated based on what you provided in the ”Service account name” field):
I granted it an “Editor” role, but you can pick an other option (read this to understand what safety options you have):
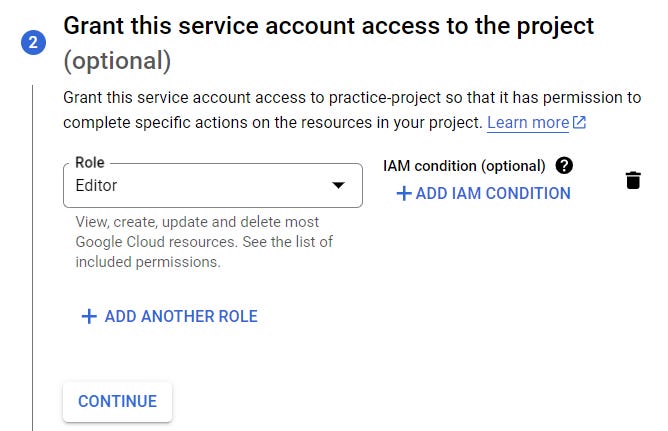
I left the rest blank and clicked “Done”, but feel free to do whatever suits you:
Under “Service accounts”, you’ll see your freshly created service account:

Click on the email part:

Choose “KEYS”, then “ADD KEY” and click on “Create new key”:
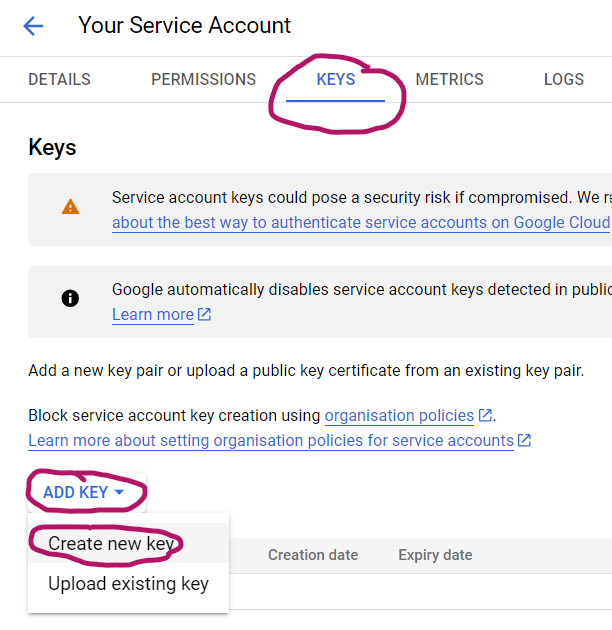
Choose “JSON” and click “Create”:

Name the file as service-account-key.json and save it into the folder where you’ll create your Python script.
Once you downloaded4 the key for your service account, you’ll see this message:

Within Google Cloud, you can find your key under “KEYS”:
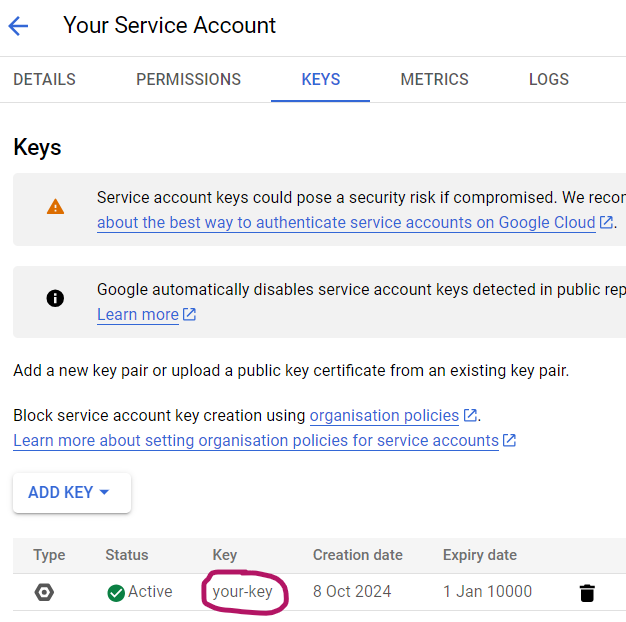
Now you have both an API key and a functioning service account.
Enough to get started with coding.
Ready to rock?
2. Finally, it’s coding time – A high-level overview of what the script does
Eventually, you’ll run this:

As you can see:
The
YouTubeVideoDataCollectorclass takes the number of videos you’d like to collect data for as input.run()actually collects the data.The first ten results get printed so you can check what the collected data look like.
Okay.
Ready to go one level deeper?
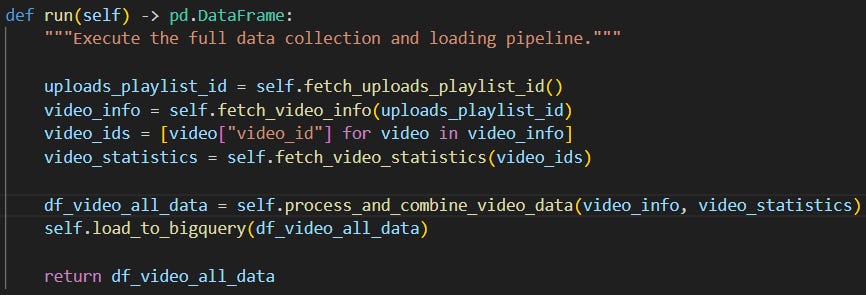
This is what run() does:
It finds the “uploads” playlist that contains all public videos of a YouTube channel.
It collects basic infos about the videos: id, title and publish date.
It saves the video ids into a list.
Based on this list it fetches video statistics: duration and view count.
It merges the basic infos and the statistics into one dataframe.
It loads the collected data into a BigQuery table.
Let’s go even deeper.
3. It’s not high-level anymore, we dive deep into the script
The sections for your convenience:
install these libraries in one line,
find a YouTube channel’s id,
set up these environment variables in
.env,tame the YouTube Data API,
understand how
YouTubeVideoDataCollectorreally, really works.
3.1 Install these libraries in one line
Run this command in your terminal:
pip install google-api-python-client pandas pandas-gbq python-dotenv3.2 Find a YouTube channel’s id
Go to a YouTube channel page,5 and click on “more”:
Scroll down a bit, click on “Share channel”, then “Copy channel ID“:
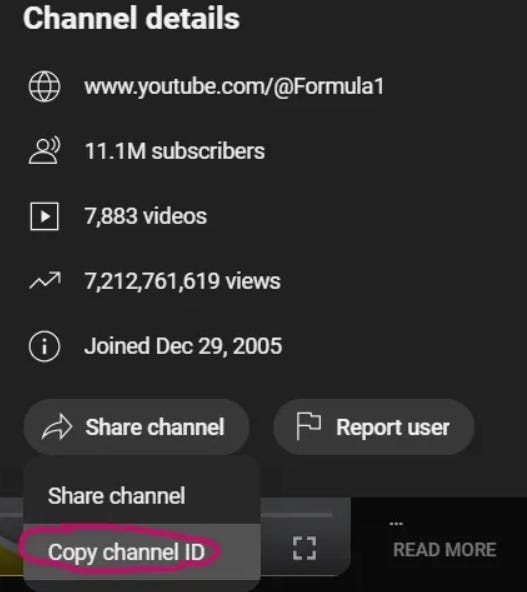
That’s it, you have the channel id.
Now, keep the id close to you, you’ll soon need it.
3.3 Set up these environment variables in .env
Create a .env file in your repo, and add four variables to it:
YOUTUBE_API_KEY=your-api-key-dont-copy-this
YOUTUBE_CHANNEL_ID=youtube-channel-id-dont-copy-this
BIGQUERY_PROJECT_ID=your-project-id-dont-copy-this
BIGQUERY_TABLE=dataset.table-dont-copy-this-the-dot-is-intentionalPaste your YouTube API key and the channel id to their respective variables.
Ignore the BigQuery variables for now. I’ll explain what these are once we get there.
Oh, and don’t forget to add .env to .gitignore!6
3.4 Tame the YouTube Data API
In the code you’ll build many YouTube API requests, so it’s a proper place here to introduce its logics.
As recommended by Google, we first build() a service object (youtube_service) in a context manager:
with build("youtube", "v3", developerKey=self.youtube_api_key) as youtube_service:
-- request comes here --build() takes the API name (youtube), the API version (v3) and your API key (youtube_api_key) as arguments.
Once you built a service object, you can make API calls, like this:
with build("youtube", "v3", developerKey=self.youtube_api_key) as youtube_service:
# API call example
channels_response = youtube_service.channels().list(
part="contentDetails",
id=self.youtube_channel_id
).execute()What comes after youtube_service is the thing you want to collect data about. It can be channel info (channels()), data about videos (videos()), etc.
Then you with methods you determine what you want to do. For example, list() gets the data we need after we define some parameters:
# Example parameters: part, id
channels_response = youtube_service.channels().list(
part="contentDetails",
id=self.youtube_channel_id
).execute()id identifies the YouTube channel to fetch data from.
part specifies what info to keep in the response. For instance, if I need a playlist id, I know7 I can find it in contentDetails, so I don’t need to request data that’s in – let’s say – contentOwnerDetails.
execute() then just performs the request.
Putting it all together, this:
youtube_service.channels().list(parameters-here).execute()just says we use the YouTube Data API (youtube_service) to get info (execute()) about a YouTube channel (channels()) by listing (list()) data (parameters within list()) about it.
Huh. 😅
This explanation was a win-win for both of us: from now own I don’t have to explain what the YouTube parts do in the code and it’s easier for you to understand what’s happening.
3.5 Understand how YouTubeVideoDataCollector really, really works
*Ladies and gentlemen, the moment you’ve all been waiting for.*
The YouTubeVideoDataCollector contains seven methods each responsible for a different step of the data collection and loading process.
I’ll explain them one-by-one.
3.5.1 The “__init__” method
def __init__(self, num_videos: int):
"""Initialize the YouTube video data collector.
Args:
num_videos: Number of videos to collect data for.
"""
# Load environment variables
load_dotenv()
self.youtube_api_key = os.getenv("YOUTUBE_API_KEY")
self.youtube_channel_id = os.getenv("YOUTUBE_CHANNEL_ID")
self.bigquery_project_id = os.getenv("BIGQUERY_PROJECT_ID")
self.bigquery_table_id = os.getenv("BIGQUERY_TABLE")
# Number of videos to collect data for
self.num_videos = num_videos
# Check for presence of required environment variables
if not all([self.youtube_api_key, self.youtube_channel_id, self.bigquery_project_id, self.bigquery_table_id]):
raise ValueError("Missing required environment variables.")The __init__ method:
loads the environment variables from
.env,checks if all the required variables are present in
.env(if not, raises an error),stores the info (
num_videos) of how how many videos we’d like to collect data for.
3.5.2 The “fetch_uploads_playlist_id” method
def fetch_uploads_playlist_id(self) -> str:
"""Fetch the uploads playlist id (playlist containing all uploaded videos on a YouTube channel)."""
with build("youtube", "v3", developerKey=self.youtube_api_key) as youtube_service:
channels_response = youtube_service.channels().list(
part="contentDetails",
id=self.youtube_channel_id
).execute()
uploads_playlist_id = channels_response["items"][0]["contentDetails"]["relatedPlaylists"]["uploads"]
return uploads_playlist_idThe fetch_uploads_playlist_id method:
gets the id of the “uploads” playlist.
This playlist holds all public videos uploaded by a channel. We need this id to know what videos are available for data collection.
In the request we use the YouTube channel id (youtube_channel_id) we had manually copied:
with build("youtube", "v3", developerKey=self.youtube_api_key) as youtube_service:
channels_response = youtube_service.channels().list(
part="contentDetails",
id=self.youtube_channel_id
).execute()3.5.3 The “fetch_video_info” method
def fetch_video_info(self, uploads_playlist_id) -> List[Dict]:
"""Fetch basic infos (title, publish datetime) about videos from the channel's uploads playlist."""
video_info = []
next_page_token = None
with build("youtube", "v3", developerKey=self.youtube_api_key) as youtube_service:
while len(video_info) < self.num_videos:
playlist_items_response = youtube_service.playlistItems().list(
part="snippet",
playlistId=uploads_playlist_id,
maxResults=min(50, self.num_videos - len(video_info)),
pageToken=next_page_token
).execute()
for item in playlist_items_response["items"]:
video_info.append({
"video_id": item["snippet"]["resourceId"]["videoId"],
"video_title": item["snippet"]["title"],
"video_publish_datetime": item["snippet"]["publishedAt"]
})
next_page_token = playlist_items_response.get("nextPageToken")
if not next_page_token:
break
return video_infoThe fetch_video_info method:
uses
uploads_playlist_idfetched by the previous method (fetch_uploads_playlist_id),to collect infos about videos in the “uploads” playlist into a list (
video_info),where each item is a dictionary of video data (id, title, publish datetime) corresponding to a video.
In this method, we build multiple requests with a while loop:
while len(video_info) < self.num_videos:
playlist_items_response = youtube_service.playlistItems().list(
part="snippet",
playlistId=uploads_playlist_id,
maxResults=min(50, self.num_videos - len(video_info)),
pageToken=next_page_token
).execute()Here’s the logic: we keep collecting video data until we have data for that many videos (num_videos) that we had defined in __init__.
Two things are interesting here: maxResults and pageToken.
In a YouTube API request, the maximum number of videos you can include is 50. In general, we can work within that limitation.
However, let’s say we want to collect data for 140 videos. In this case the last request should contain 40 (instead of 50) in maxResults.
We handle such cases with this line:
maxResults=min(50, self.num_videos - len(video_info))This line checks how many videos we already collected data for (len(video_info)) and for how many we still need to fetch data (self.num_videos - len(video_info)).
If we still need data for 50 or more videos, we use 50 in maxResults. Otherwise we request data for less than 50 videos.
An example could be for 140 videos where we already collected data for 100 videos:
# maxResults will be 40 here
maxResults=min(50, 40)Moving onto pageToken:
pageToken=next_page_tokenBecause there’s a limitation of getting data for a maximum of 50 videos in a response, somehow we need to know if there’s more videos we can request data for.
The YouTube API solves this issue with page tokens.
If there’s nextPageToken in the response, we know there’s more videos we should check, so we can use its value to get the next set of video results with our next request:
next_page_token = playlist_items_response.get("nextPageToken")If nextPageToken is absent from the API response, we stop collecting data, because there’s no more video to collect data about:
if not next_page_token:
breakBut as long as we find videos, we save their id, title and publish datetime into the video_info list:
for item in playlist_items_response["items"]:
video_info.append({
"video_id": item["snippet"]["resourceId"]["videoId"],
"video_title": item["snippet"]["title"],
"video_publish_datetime": item["snippet"]["publishedAt"]
})3.5.4 The “fetch_video_statistics“ method
def fetch_video_statistics(self, video_ids: List[str]) -> List[Dict]:
"""Fetch statistics (duration, view count) for a list of video IDs."""
video_statistics = []
batch_size = 50
with build("youtube", "v3", developerKey=self.youtube_api_key) as youtube_service:
for i in range(0, len(video_ids), batch_size):
batch = video_ids[i:i + batch_size]
videos_response = youtube_service.videos().list(
part="contentDetails,statistics",
id=",".join(batch)
).execute()
for video in videos_response["items"]:
video_statistics.append({
"video_id": video["id"],
"video_duration": video["contentDetails"]["duration"],
"video_view_count": video["statistics"]["viewCount"]
})
return video_statisticsThe fetch_video_statistics method:
uses
video_idsto collect duration8 and view count infos about videos we identified withfetch_video_infoin the previous step,and stores these (together with video ids) as dictionaries in a list called
video_statistics.
It still holds true that we can request a maximum of 50 items at once.
Unfortunately, we can’t use maxResults this time, because the API call expects a string in which video ids are separated by commas (like “id_1,id_2,id_n”).
And exactly that’s why we need the video_ids list; this is where these kind of requests identify what videos to collect data for.
The approach for handling fewer than 50 videos differs from the fetch_video_info method, though the end result is the same:
for i in range(0, len(video_ids), batch_size):
batch = video_ids[i:i + batch_size]Finally we just add the collected data to a list (video_statistics):
for video in videos_response["items"]:
video_statistics.append({
"video_id": video["id"],
"video_duration": video["contentDetails"]["duration"],
"video_view_count": video["statistics"]["viewCount"]
})3.5.5 The “process_and_combine_video_data” method
def process_and_combine_video_data(self, video_info: List[Dict], video_statistics: List[Dict]) -> pd.DataFrame:
"""Process and combine video info and statistics into a single DataFrame."""
df_video_info = pd.DataFrame(video_info)
df_video_statistics = pd.DataFrame(video_statistics)
df_video_all_data = (
df_video_info.merge(df_video_statistics, how="inner", on="video_id")
.assign(
video_publish_datetime=lambda df_: pd.to_datetime(df_["video_publish_datetime"]),
video_view_count=lambda df_: df_["video_view_count"].astype("int")
)
)
return df_video_all_dataThe process_and_combine_video_data method:
creates dataframes from the
video_infoand thevideo_statisticslists,and unites them into one final dataframe (
df_video_all_data) so we have all data we collected for the videos in one place.
While creating df_video_all_data, we convert the publish datetime data to datetime and the video view count to integers (both originally strings):
.assign(
video_publish_datetime=lambda df_: pd.to_datetime(df_["video_publish_datetime"]),
video_view_count=lambda df_: df_["video_view_count"].astype("int")
)3.5.6 The “load_to_bigquery” method
def load_to_bigquery(self, df_video_all_data: pd.DataFrame) -> None:
"""Load the processed DataFrame to BigQuery."""
credentials = service_account.Credentials.from_service_account_file(
"service-account-key.json"
)
pandas_gbq.to_gbq(
df_video_all_data,
self.bigquery_table_id,
project_id=self.bigquery_project_id,
if_exists="replace",
credentials=credentials
)The load_to_bigquery method:
loads your service account credentials file (
credentials) so the script can access9 your BigQuery account,loads
df_video_all_datainto a BigQuery table usingpandas_gbq.to_gbq,totally replacing (
if_exists=”replace”) the content of the table if it’s not your first run.
For this to work, you’ll need to create a BigQuery table. I explain everything in the “4. Create a BigQuery table where you can store your collected data“ section.
But if you don’t feel like doing the BigQuery part, just rewrite the code to export df_video_all_data into a CSV or print it out or whatever you wish. 🙂
3.5.7 The “run” method
def run(self) -> pd.DataFrame:
"""Execute the full data collection and loading pipeline."""
uploads_playlist_id = self.fetch_uploads_playlist_id()
video_info = self.fetch_video_info(uploads_playlist_id)
video_ids = [video["video_id"] for video in video_info]
video_statistics = self.fetch_video_statistics(video_ids)
df_video_all_data = self.process_and_combine_video_data(video_info, video_statistics)
self.load_to_bigquery(df_video_all_data)
return df_video_all_dataThe run method:
puts everything together.
I won’t explain it in detail, because now you should understand what each method does in what order.
run() just runs the whole process when you call it:
4. Create a BigQuery table where you can store your collected data
First, you need to create a project. A project is the basis for doing anything within Google Cloud.
If you have a Google Cloud account, you already should have one. If not, here’s how you can create a project.
Get your project id by clicking on your project’s name in the menu, then add it to your .env file (BIGQUERY_PROJECT_ID):
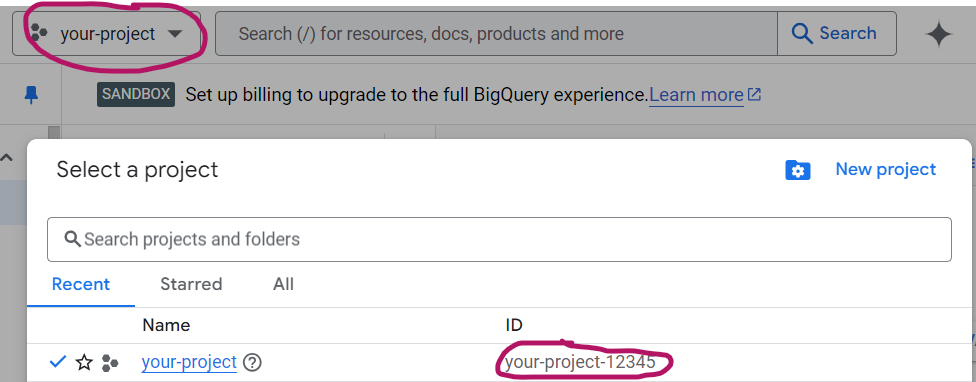
In your project, go to BigQuery:
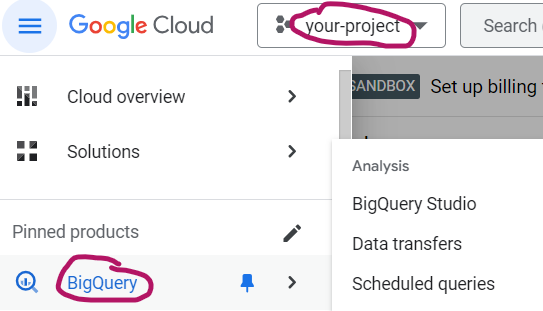
Next to your project, click on the three dots and choose “Create data set”:
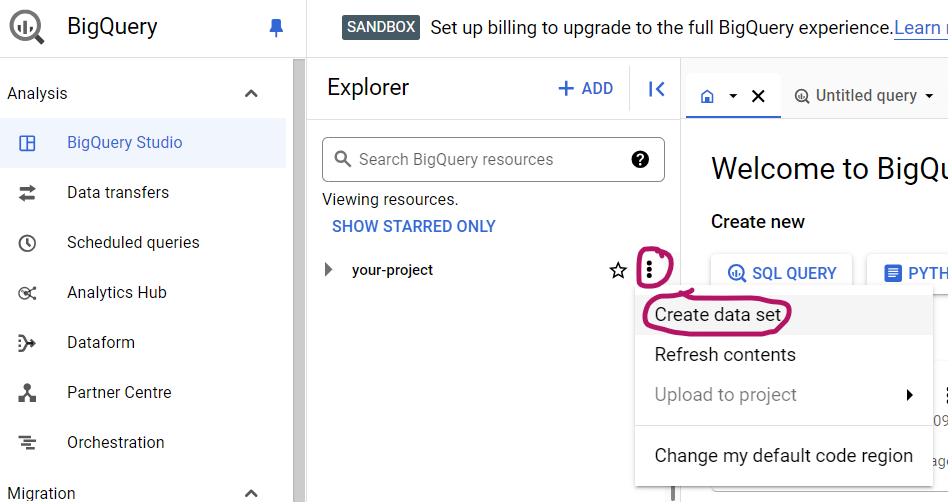
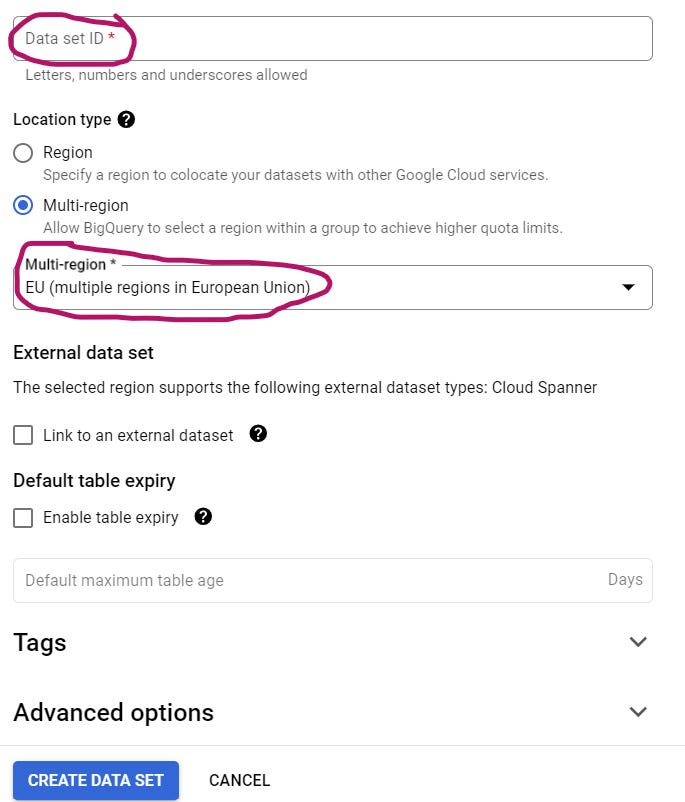
Name your data set (like “youtube_data”), pick a region or multi-region where your table will exist (e.g. choose EU if you’re in the EU), then create the data set:
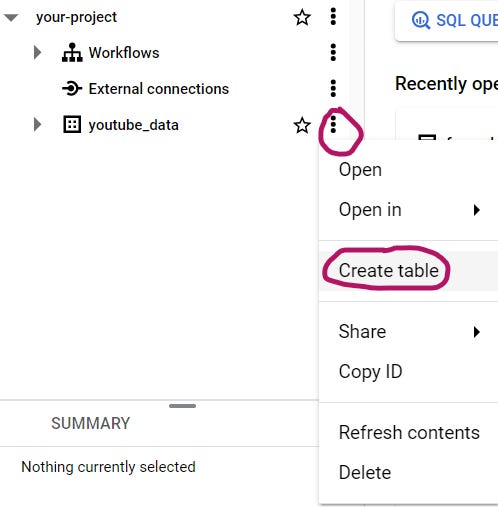
Now your data set should appear. Click the three dots next to it, then “Create table“:
Give your table a name, set your table’s column names and data types under "Schema”, then create the table:
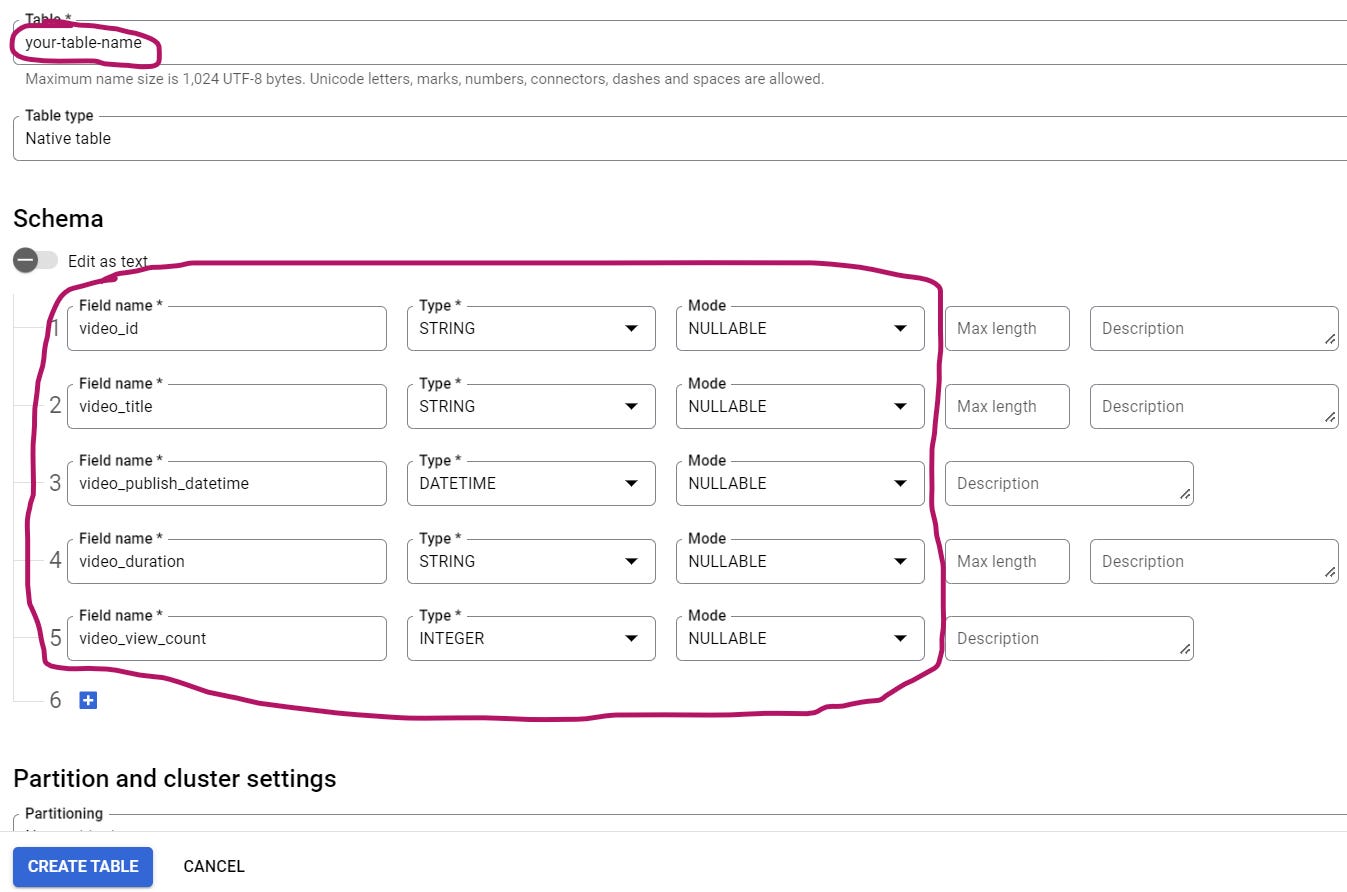
Get your table id by copying its id:
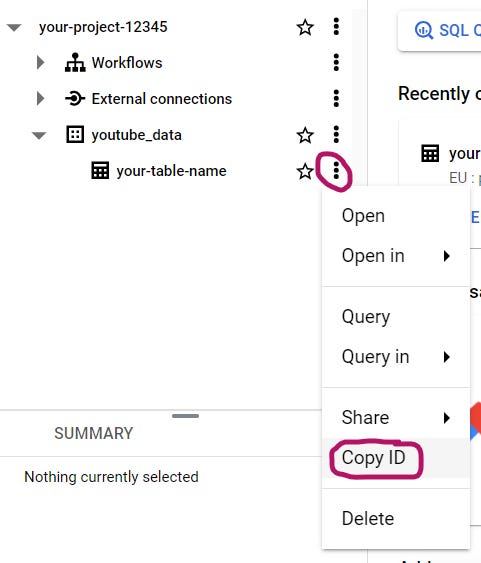
The copied id will look similar to this:
your-project-12345.youtube_data.your-table-nameKeep only the part coming after the first dot:
youtube_data.your-table-nameAnd add it to your .env (BIGQUERY_TABLE).
Now you can run the Python script we’ve been building throughout the article.
After it ran, click “PREVIEW” in your table, and you should see the collected YouTube video data:
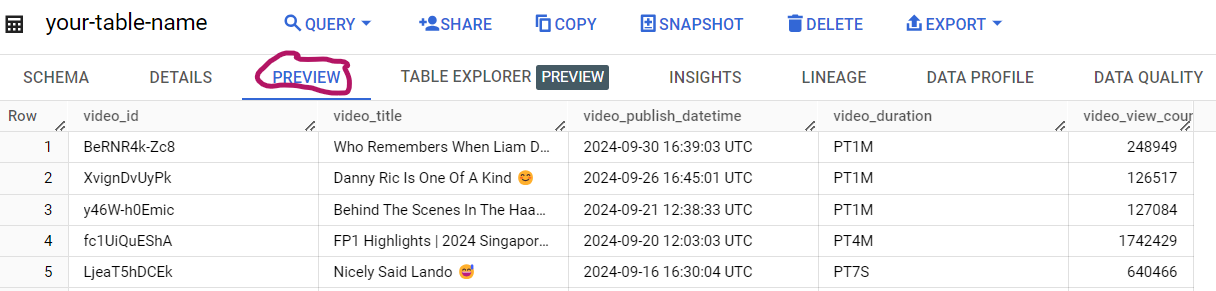
Isn’t it beautiful…? 🥲
5. So what?
Is this even a real question?
You learned a TON:
how to create an API key and a service account in Google Cloud,
how to use the YouTube API to collect video data,
and how to load data to BigQuery.
These are some useful things to know, so be proud of yourself!
Anyways.
If you have any questions/comments, just drop ‘em here, DM me on Substack or hit me up on LinkedIn!
And have an awesome day! ✌️
Btw, I honestly believe that a project is cooler if you own the whole thing, like creating or collecting your own data, and not just using something that someone else put out there.
Although I’d argue even more.
Don’t even ask – I’m not available for design-related jobs, sorry.
Here’s some best practices by Google for managing service account keys.
Formula 1 cars are beautiful, aren’t they?
If you don’t know what .gitignore is, then either 1) Google it and start using it or 2) you probably don’t use version tracking, so you can ignore it totally. Just don’t share your .env file with anyone, not even if they say “you can trust me, I’m your friend”.
Once you run the full script, you’ll see that video duration is stored in a strange format. Here’s the explanation: “The tag value is an ISO 8601 duration in the format PT#M#S, in which the letters PT indicate that the value specifies a period of time, and the letters M and S refer to length in minutes and seconds, respectively. The # characters preceding the M and S letters are both integers that specify the number of minutes (or seconds) of the video.“
During the first run I had to manually authorize the script, but after that it works without the manual intervention. So be prepared for this.
Having my data on BigQuery makes me so happy (can't explain why)
Great guide Tamás. I used to work exclusively with Youtube data in my previous job, but luckily for me, all of the data I needed was just there, sitting on BigQuery, waiting for me to query it.
But I think I will need to do something like this for one of my mentees, so I'll refer back to this guide.
It is actually so detailed article I loved it. Hats off to your work