
Build an ML-ready dataset with Python and BigQuery
Hands-on end-to-end ML project for the busy learner – Part II

You don’t want to ruin your awesome machine learning (ML) model by feeding it garbage.
Nah, you’re better than that.
You familiarize yourself with what data you have and come up with ways to make it less garbage.
So you and your ML model can (hopefully) get the praise you deserve. ❤️
In Part II of this series, you’ll learn to:
load the video data collected from Part I in BigQuery,
do some basic feature engineering to create an input dataset for an ML model,1
save this new dataset back to BigQuery,
and put this all together in a pipeline you can run at the press of a button.
One more thing!
I’ll assume you’ve already read and completed Part I; if not, please go through that article first (or just enjoy reading this one if you feel like it).
Other than that, let’s get down to it (link to the Python file in the repo).
1. A high-level overview of what the script does
Here’s what you’ll run at the end:
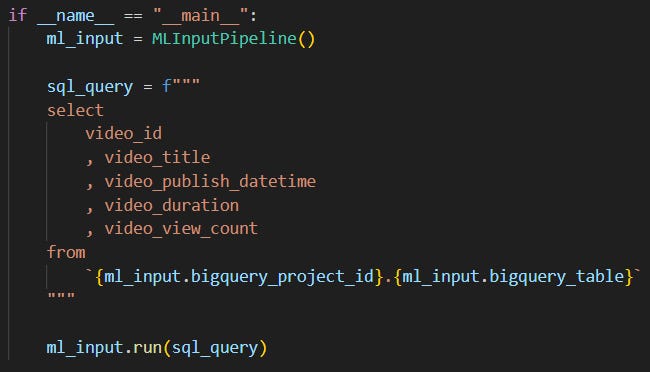
The script:
creates
ml_inputcontaining everything needed for the pipeline,uses
sql_queryto load the raw YouTube data from BigQuery collected in Part I,runs the whole pipeline that outputs a new table into BigQuery that we’ll use to train an ML model on in Part III.
run() performs the following steps:
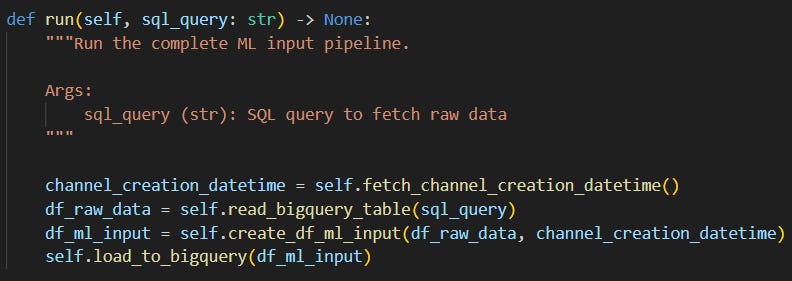
It fetches when the YouTube channel we’re gathering data from was created (we’ll use this info to create a feature for the ML model, more on this later).
Using
sql_query, it loads the raw data table from BigQuery (created in Part I) into a pandas dataframe.It creates a new dataframe (
df_ml_input) that contains features that the ML model will use for training. The features are derived from the videos’ publish datetimes and titles as numerical values.Finally, it loads this new dataframe into BigQuery.
Let’s look under the hood!
2. Let’s build the pipeline step-by-step
We have one big-boss-class (MLInputPipeline) housing everything pipeline-related.
You need to load a table from BigQuery?
MLInputPipeline‘s got you covered.
You need to engineer new features for your ML model?
MLInputPipeline‘s got what you’re lookin’ for.
You get the idea.
Okay. So.
Let’s go over each of its methods one-by-one to better understand what’s doing what.
2.1 The “__init__()” method
def __init__(self):
"""Initialize the MLInputPipeline class."""
# Load environment variables
load_dotenv()
self.youtube_api_key = os.getenv("YOUTUBE_API_KEY")
self.youtube_channel_id = os.getenv("YOUTUBE_CHANNEL_ID")
self.bigquery_project_id = os.getenv("BIGQUERY_PROJECT_ID")
self.bigquery_table=os.getenv("BIGQUERY_TABLE")
self.bigquery_ml_input_table = os.getenv("BIGQUERY_ML_INPUT_TABLE")
self.credentials = service_account.Credentials.from_service_account_file(
"service-account-key.json"
)
# Check for presence of required environment variables
if not all([self.youtube_api_key, self.youtube_channel_id, self.bigquery_project_id, self.bigquery_table, self.bigquery_ml_input_table, self.credentials]):
raise ValueError("Missing required environment variables.")The __init__() method:
loads your BigQuery credentials and the environment variables used in the pipeline: most of them were created in Part I, the only new addition is
BIGQUERY_ML_INPUT_TABLE; you’ll create it in the “3.1 Create the “ml-input” table in BigQuery” section,checks whether all required environment variables are present; if not, an error is raised to let you know.
2.2 The “fetch_channel_creation_datetime()” method
def fetch_channel_creation_datetime(self) -> datetime:
"""Fetch channel creation datetime from YouTube API.
Returns:
datetime: Channel creation datetime
"""
with build("youtube", "v3", developerKey=self.youtube_api_key) as youtube_service:
channels_response = youtube_service.channels().list(
part="snippet",
id=self.youtube_channel_id
).execute()
channel_creation_datetime_str = channels_response["items"][0]["snippet"]["publishedAt"]
channel_creation_datetime = pd.to_datetime(channel_creation_datetime_str)
return channel_creation_datetimeThe fetch_channel_creation_datetime() method:
uses the YouTube Data API to collect when the YouTube channel was created (e.g. “2005-12-29T00:34:38Z”),
and converts it to a pandas datetime object.
We’ll use this info to create a feature for the ML model (more details under the create_df_ml_input() method).
2.3 The “read_bigquery_table()” method
def read_bigquery_table(self, sql_query: str) -> pd.DataFrame:
"""Read data from BigQuery table.
Args:
sql_query (str): SQL query to execute
Returns:
pd.DataFrame: Query results as DataFrame
"""
df = pandas_gbq.read_gbq(
sql_query,
project_id=self.bigquery_project_id,
credentials=self.credentials
)
return dfThe read_bigquery_table() method:
receives an SQL query as input,
connects to your BigQuery project you defined in
.env,reads (using the SQL query) the BigQuery table storing the original raw video data from Part I,
and saves the resulting table into a pandas dataframe,
so the rest of the script can create new features from this raw data.
2.4 The “_map_hour_to_time_of_day()” method
def _map_hour_to_time_of_day(self, hour: int) -> int:
"""Map hour to time of day category.
Args:
hour (int): Hour of day (0-23)
Returns:
int: Time of day category (0: Morning, 1: Afternoon, 2: Evening, 3: Night)
"""
if 5 <= hour <= 11:
return 0 # Morning
elif 12 <= hour <= 16:
return 1 # Afternoon
elif 17 <= hour <= 20:
return 2 # Evening
else:
return 3 # NightThe _map_hour_to_time_of_day() method:
is used by the next method (
create_df_ml_input()),to create a new feature called “time_of_day”,
that categorizes the video’s publish hour (e.g. 16 (=4 pm)) into one of the four time of day categories: 0 (morning), 1 (afternoon), 2 (evening) or 4 (night).2
You may have noticed that this method starts with a “_”. It’s a private method, which means it shouldn’t be accessed outside MLInputPipeline.
But honestly, for this script you can leave the “_”. It’s just something I added to it.
2.5 The “create_df_ml_input()” method
def create_df_ml_input(self, df: pd.DataFrame, channel_creation_datetime: datetime) -> pd.DataFrame:
"""Create ML input DataFrame with engineered features.
Args:
df (pd.DataFrame): Raw data DataFrame
channel_creation_datetime (datetime): Channel creation datetime
Returns:
pd.DataFrame: DataFrame with engineered features
"""
df = df.copy()
df = (
df.assign(
duration_seconds=lambda df_: df_["video_duration"].apply(lambda x: isodate.parse_duration(x).total_seconds()).astype("int"),
publish_year=lambda df_: df_["video_publish_datetime"].dt.year,
publish_month=lambda df_: df_["video_publish_datetime"].dt.month,
publish_quarter=lambda df_: df_["video_publish_datetime"].dt.quarter,
publish_day=lambda df_: df_["video_publish_datetime"].dt.day,
publish_day_of_week=lambda df_: df_["video_publish_datetime"].dt.day_of_week,
publish_hour=lambda df_: df_["video_publish_datetime"].dt.hour,
publish_is_weekend=lambda df_: df_["publish_day_of_week"].apply(lambda x: 1 if x >= 5 else 0),
publish_time_of_day=lambda df_: df_["publish_hour"].apply(self._map_hour_to_time_of_day),
days_since_channel_creation=lambda df_: df_["video_publish_datetime"].sub(channel_creation_datetime).dt.days,
title_length=lambda df_: df_["video_title"].apply(lambda x: len(x)),
title_word_count=lambda df_: df_["video_title"].apply(lambda x: len(str(x).split())),
title_sentiment_score=lambda df_: df_["video_title"].apply(lambda x: round(TextBlob(x).sentiment.polarity, 2)),
)
.rename(columns={
"video_id":"id",
"video_view_count":"view_count"
})
.drop(columns=["video_duration", "video_publish_datetime", "video_title"])
)
return dfHuh, that was a lot, wasn’t it…? 😅
The create_df_ml_input() method:
creates all features from the raw dataframe loaded by
read_bigquery_table()that the ML model will be trained on,performs
df = df.copy()as a precaution to not modify the original dataframe,creates the new features with
assign(); the feature/column names are pretty self-explanatory so I’ll explain only the tricky ones:“duration_seconds”: since the original duration data is in ISO 8601 duration format (e.g. PT3M5S), we convert it to seconds with the help of isodate3 (e.g. PT3M5S becomes 185 (seconds): 3M (3 minutes * 60 seconds = 180 seconds) + 5S (5 seconds)),
“publish_day_of_week”: an integer marking each day between 0 and 6, where 0 marks Sunday,
“publish_is_weekend”: 1 if the publish day is Saturday or Sunday, 0 if it’s a weekday,
“publish_time_of_day”: this is where the script uses
_map_hour_to_time_of_day()to assign a time of day marked by an integer between 1 and 4 to the publish hour,“days_since_channel_creation”: this calculates how many days passed between the publication date of the video and the YouTube channel’s creation; since we don’t have access to how many subscribers the channel had at the publication date of a video, this number might be our next-best bet: the older the YouTube channel the more subscribers it possibly has so the videos might get more views,
“title_sentiment_score”: we use TextBlob to do sentiment analysis on the video titles; for each title we get the title’s sentiment score (polarity) as a float number between -1 and 1; polarity expresses textual emotion which in TextBlob’s case means positive if closer to 1, negative if closer to -1 and neutral if close to 0,
with
rename()the script renames some original columns removing the “video” part from them since we know these data are about videos (e.g. from “video_id” to “id”),drop()removes columns we don’t need anymore,and just like that, the ML input dataframe is ready!
Note 1.: To be able to create “duration_seconds” and “title_sentiment_score”, make sure you:
pip install isodate textblobNote 2.: I’m pretty sure that a way better dataset can be engineered for ML models through an iterative process; this example just shows that many more features can be easily created from an existing dataset.
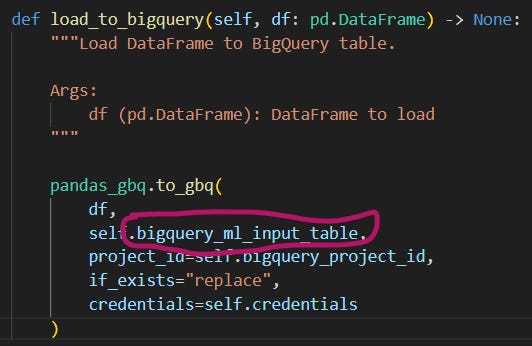
2.6 The “load_to_bigquery()” method
def load_to_bigquery(self, df: pd.DataFrame) -> None:
"""Load DataFrame to BigQuery table.
Args:
df (pd.DataFrame): DataFrame to load
"""
pandas_gbq.to_gbq(
df,
self.bigquery_ml_input_table,
project_id=self.bigquery_project_id,
if_exists="replace",
credentials=self.credentials
)The load_to_bigquery() method:
receives the dataframe created by
create_df_ml_input(),saves it to your BigQuery project as a table,
so now you can access the input table for the ML model from BigQuery!
2.7 The “run()” method
def run(self, sql_query: str) -> None:
"""Run the complete ML input pipeline.
Args:
sql_query (str): SQL query to fetch raw data
"""
channel_creation_datetime = self.fetch_channel_creation_datetime()
df_raw_data = self.read_bigquery_table(sql_query)
df_ml_input = self.create_df_ml_input(df_raw_data, channel_creation_datetime)
self.load_to_bigquery(df_ml_input)The run() method:
runs the whole ML input table creation pipeline we’ve just went through.
So once you run the script:
You’ll have a a nice table waiting for you in BigQuery like this:

Of course, first you’ll have to prepare BigQuery for welcoming this table.
3. Set up your ML input table in BigQuery, modify your .env, too
3.1 Create the “ml-input” table in BigQuery
Before you run the whole pipeline, create a new table called ml-input (or whatever you like) in BigQuery with the below schema settings:
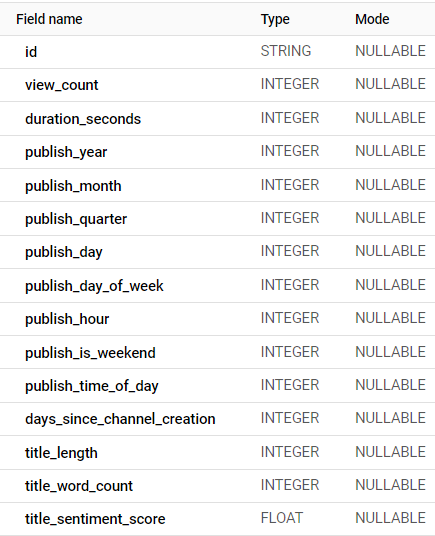
(If you need a hint on how to create a new table in BigQuery, check this part of the previous article in the series.)
Once you’re done, you’ll also need to update your .env.
3.2 Add “BIGQUERY_ML_INPUT_TABLE” to .env
Add a new variable called BIGQUERY_ML_INPUT_TABLE to your .env, and just like you did with BIGQUERY_TABLE in Part I, define its value like this:
youtube_data.your-table-nameThis is needed the load_to_bigquery() method will know which table to save the dataframe into:
As a double-check, your .env should look like this:
YOUTUBE_API_KEY=your-api-key-dont-copy-this
YOUTUBE_CHANNEL_ID=youtube-channel-id-dont-copy-this
BIGQUERY_PROJECT_ID=your-project-id-dont-copy-this
BIGQUERY_TABLE=dataset.table-dont-copy-this-the-dot-is-intentional
BIGQUERY_ML_INPUT_TABLE=dataset.ml-input-table-dont-copy-this-the-dot-is-intentional4. So what?
You learned to build a basic pipeline for creating an input dataset for a ML model by:
reading raw data from BigQuery,
engineering new features with pandas,
and exporting this dataset to BigQuery with Python.
Next time, we’ll train our ML model – excited yet? 😏
Anyways.
If you have any questions/comments, just drop ‘em here, DM me on Substack or hit me up on LinkedIn!
And have an awesome day! ✌️
That will predict a video’s view count!
You see, dealing with time-related features is a tricky one; these are cyclical features and there are better ways to handle them. For convenience, I kept them as numerical values, but at a later iteration of the article I may update it to better handle cyclical values.
Yep, a Stack Overflow link – looks like someone’s been Googling instead of using a LLM? 🧐